 数学理论基础
数学理论基础
# 概述
本科生做机器学习
文凭本身倒不是关键,只是研究生相对来说机器学习可以研究得稍微更深入,如果还有做过科研项目啥的,经验稍微更足。本科教育还是偏向基础,知识面求广不求深。一般的本科生机器学习没有学得很深,特别是导师知道我不准备读研的话,都不给活干了。
现在机器学习岗位一般都要求研究生,本科生如果没有特别牛可能简历筛选都过不了。这是一个大问题。从企业的角度来说是合理的,绝大部分本科生我想是没有能力胜任机器学习工作的。这玩意又不是培训个一两个月就能玩得溜,浪费1年时间来慢慢培养?企业又不是做慈善,直接招一个研究生有啥不好?
对于能力方面,coursera上Andrew Ng的《Machine Learning》 、 台大的《机器学习基石》 《机器学习技法》啥的老老实实学好,再参加kaggle之类的比赛实际练练,拿个好名次,其实就差不多能胜任实际工作了,干起活来跟研究生也没多大差别。sklearn这个库不错,可以学习学习。毕竟工业界还是搞业务,不是搞科研。平时工作相关用的论文能看懂和实现一下就可以了,轮子啥的一般不需要你去发明,搞懂最基本的原理,能当个调参侠,调包客就可以了。听过一些读研的分享研究生做的一些工作,有些离实际是挺远的,没啥卵用。而且不少研究生也挺菜的,所以也不必为了学历的问题妄自菲薄。
什么是机器学习
我们知道,机器学习的特点就是:以计算机为工具和平台,以数据为研究对象,以学习方法为中心;是概率论、线性代数、数值计算、信息论、最优化理论和计算机科学等多个领域的交叉学科。所以本文就先介绍一下机器学习涉及到的一些最常用的的数学知识。
# 线性代数
标量
一个标量就是一个单独的数,一般用小写变量名称表示。
向量
一个向量就是一列数,这些数是有序排列的。通过次序中的索引,我们可以确定每个单独的数。通常会赋予向量粗体的小写名称。当我们需要明确表示向量中的元素时,我们会将元素排 列成一个方括号包围的纵柱:

我们可以把向量看作空间中的点,每个元素是不同的坐标轴上的坐标。
矩阵
矩阵是二维数组,其中的每一个元素被两个索引而非一个所确定。我们通常会赋予矩阵粗体的大写变量名称,比如A。 如果一个实数矩阵高度为m,宽度为n,那么我们说
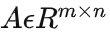

矩阵这东西在机器学习中就不要太重要了!实际上,如果我们现在有N个用户的数据,每条数据含有M个特征,那其实它对应的就是一个NM的矩阵呀;再比如,一张图由1616的像素点组成,那这就是一个16*16的矩阵了。现在才发现,我们大一学的矩阵原理原来这么的有用!要是当时老师讲课的时候先普及一下,也不至于很多同学学矩阵的时候觉得莫名其妙了。
张量
几何代数中定义的张量是基于向量和矩阵的推广,通俗一点理解的话,我们可以将标量视为零阶张量,矢量视为一阶张量,那么矩阵就是二阶张量。例如,可以将任意一张彩色图片表示成一个三阶张量,三个维度分别是图片的高度、宽度和色彩数据。将这张图用张量表示出来,就是最下方的那张表格:

其中表的横轴表示图片的宽度值,这里只截取0~319;表的纵轴表示图片的高度值,这里只截取0~4;表格中每个方格代表一个像素点,比如第一行第一列的表格数据为
[1.0,1.0,1.0],代表的就是RGB三原色在图片的这个位置的取值情况(即R=1.0,G=1.0,B=1.0)。当然我们还可以将这一定义继续扩展,即:我们可以用四阶张量表示一个包含多张图片的数据集,这四个维度分别是:图片在数据集中的编号,图片高度、宽度,以及色彩数据。
张量在深度学习中是一个很重要的概念,因为它是一个深度学习框架中的一个核心组件,后续的所有运算和优化算法几乎都是基于张量进行的。
范数
有时我们需要衡量一个向量的大小。在机器学习中,我们经常使用被称为范数(norm) 的函数衡量矩阵大小。
Lp 范数如下:
这里先说明一下,在机器学习中,
L1范数和L2范数很常见,主要用在损失函数中起到一个限制模型参数复杂度的作用,至于为什么要限制模型的复杂度,这又涉及到机器学习中常见的过拟合问题。具体的概念在后续文章中会有详细的说明和推导,大家先记住:这个东西很重要,实际中经常会涉及到,面试中也常会被问到!特征分解
许多数学对象可以通过将它们分解成多个组成部分。特征分解是使用最广的矩阵分解之一,即将矩阵分解成一组特征向量和特征值。

奇异值分解(Singular Value Decomposition,SVD)
矩阵的特征分解是有前提条件的,那就是只有对可对角化的矩阵才可以进行特征分解。但实际中很多矩阵往往不满足这一条件,甚至很多矩阵都不是方阵,就是说连矩阵行和列的数目都不相等。这时候怎么办呢?人们将矩阵的特征分解进行推广,得到了一种叫作“矩阵的奇异值分解”的方法,简称SVD。通过奇异分解,我们会得到一些类似于特征分解的信息。它的具体做法是将一个普通矩阵分解为奇异向量和奇异值。比如将矩阵A分解成三个矩阵的乘积:

这些矩阵每一个都拥有特殊的结构,其中U和V都是正交矩阵,D是对角矩阵(注意,D不一定是方阵)。对角矩阵D对角线上的元素被称为矩阵A的奇异值。矩阵U的列向量被称为左奇异向量,矩阵V 的列向量被称右奇异向量。
SVD最有用的一个性质可能是拓展矩阵求逆到非方矩阵上。另外,SVD可用于推荐系统中。
Moore-Penrose伪逆
对于非方矩阵而言,其逆矩阵没有定义。假设在下面问题中,我们想通过矩阵A的左逆B来求解线性方程:

其中,矩阵U,D 和V 是矩阵A奇异值分解后得到的矩阵。对角矩阵D 的伪逆D+ 是其非零元素取倒之后再转置得到的。
几种常用的距离
上面大致说过, 在机器学习里,我们的运算一般都是基于向量的,一条用户具有100个特征,那么他对应的就是一个100维的向量,通过计算两个用户对应向量之间的距离值大小,有时候能反映出这两个用户的相似程度。这在后面的KNN算法和K-means算法中很明显。
- 曼哈顿距离

from numpy import * vector1 = mat([1,2,3]) vector2 = mat([4,5,6]) print sum(abs(vector1-vector2))1
2
3
4- 欧氏距离

from numpy import * vector1 = mat([1,2,3]) vector2 = mat([4,5,6]) print sqrt((vector1-vector2)*(vector1-vector2).T)1
2
3
4- 闵可夫斯基距离

- 切比雪夫距离

from numpy import * vector1 = mat([1,2,3]) vector2 = mat([4,5,6]) print sqrt(abs(vector1-vector2).max)1
2
3
4- 夹角余弦

from numpy import * vector1 = mat([1,2,3]) vector2 = mat([4,5,6]) print dot(vector1,vector2)/(linalg.norm(vector1)*linalg.norm(vector2))1
2
3
4- 汉明距离
汉明距离定义的是两个字符串中不相同位数的数目。
例如:字符串‘1111’与‘1001’之间的汉明距离为2。
信息编码中一般应使得编码间的汉明距离尽可能的小。
from numpy import * matV = mat([1,1,1,1],[1,0,0,1]) smstr = nonzero(matV[0]-matV[1]) print smstr1
2
3
4- 杰卡德相似系数

- 杰卡德距离

from numpy import * import scipy.spatial.distance as dist matV = mat([1,1,1,1],[1,0,0,1]) print dist.pdist(matV,'jaccard')1
2
3
4
# 概率
为什么使用概率
概率论是用于表示不确定性陈述的数学框架,即它是对事物不确定性的度量。
在人工智能领域,我们主要以两种方式来使用概率论。首先,概率法则告诉我们AI系统应该如何推理,所以我们设计一些算法来计算或者近似由概率论导出的表达式。其次,我们可以用概率和统计从理论上分析我们提出的AI系统的行为。
计算机科学的许多分支处理的对象都是完全确定的实体,但机器学习却大量使用概率论。实际上如果你了解机器学习的工作原理你就会觉得这个很正常。因为机器学习大部分时候处理的都是不确定量或随机量。
随机变量
随机变量可以随机地取不同值的变量。我们通常用小写字母来表示随机变量本身,而用带数字下标的小写字母来表示随机变量能够取到的值。例如,x1 和x2 都是随机变量X可能的取值。
对于向量值变量,我们会将随机变量写成X,它的一个值为x。就其本身而言,一个随机变量只是对可能的状态的描述;它必须伴随着一个概率分布来指定每个状态的可能性。
随机变量可以是离散的或者连续的。
概率分布
给定某随机变量的取值范围,概率分布就是导致该随机事件出现的可能性。
从机器学习的角度来看,概率分布就是符合随机变量取值范围的某个对象属于某个类别或服从某种趋势的可能性。
条件概率

贝叶斯公式
先看看什么是“先验概率”和“后验概率”,以一个例子来说明:
假设某种病在人群中的发病率是0.001,即1000人中大概会有1个人得病,则有: P(患病) = 0.1%;即:在没有做检验之前,我们预计的患病率为P(患病)=0.1%,这个就叫作"先验概率"。
再假设现在有一种该病的检测方法,其检测的准确率为95%;即:如果真的得了这种病,该检测法有95%的概率会检测出阳性,但也有5%的概率检测出阴性;或者反过来说,但如果没有得病,采用该方法有95%的概率检测出阴性,但也有5%的概率检测为阳性。用概率条件概率表示即为:P(显示阳性|患病)=95%
现在我们想知道的是:在做完检测显示为阳性后,某人的患病率P(患病|显示阳性),这个其实就称为"后验概率"。
而这个叫贝叶斯的人其实就是为我们提供了一种可以利用先验概率计算后验概率的方法,我们将其称为“贝叶斯公式”。
这里先了解条件概率公式:

贝叶斯公式贯穿了机器学习中随机问题分析的全过程。从文本分类到概率图模型,其基本分类都是贝叶斯公式。
期望

方差
概率中,方差用来衡量随机变量与其数学期望之间的偏离程度;统计中的方差为样本方差,是各个样本数据分别与其平均数之差的平方和的平均数。数学表达式如下:

协方差

期望、方差、协方差
期望、方差、协方差等主要反映数据的统计特征,机器学习的一个很大应用就是数据挖掘等,因此这些基本的统计概念也是很有必要掌握。另外,像后面的EM算法中,就需要用到期望的相关概念和性质。
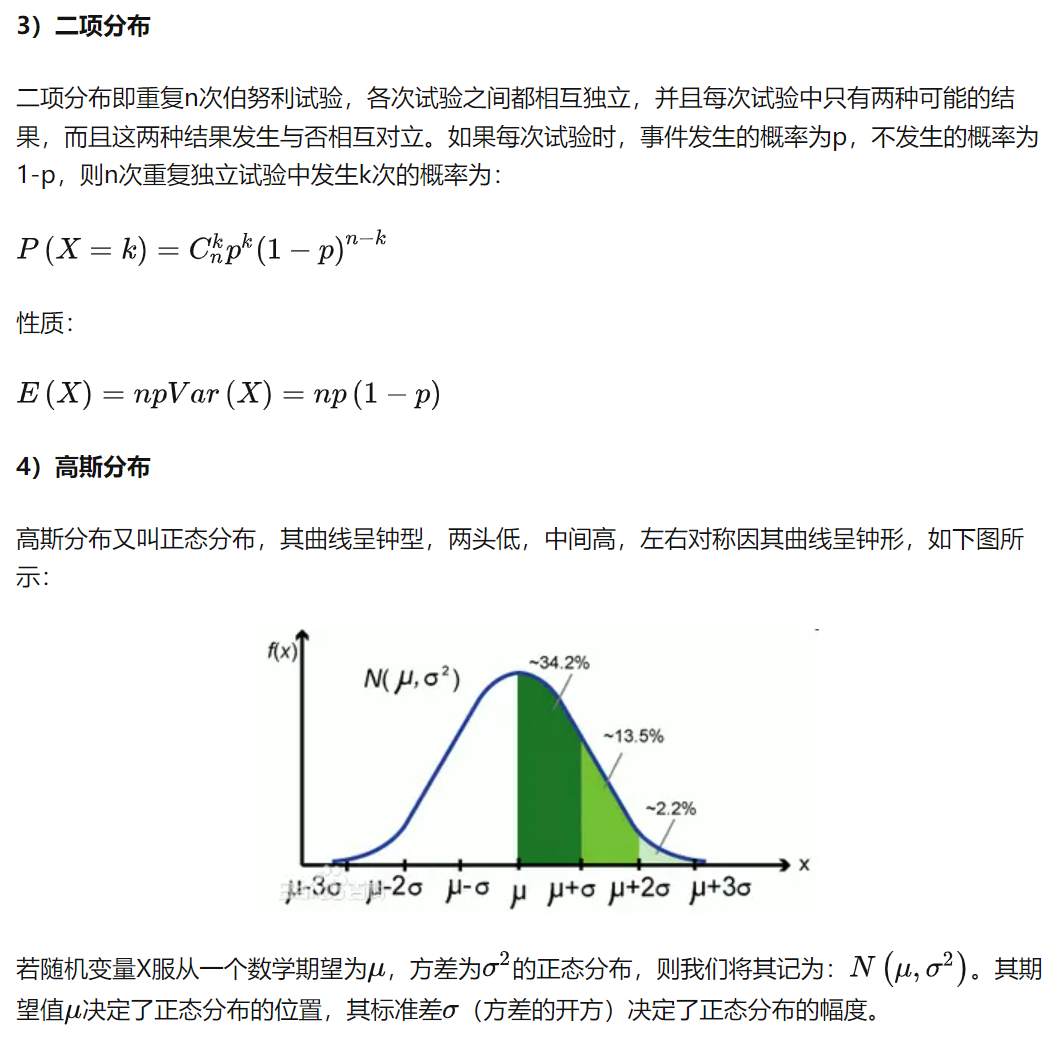
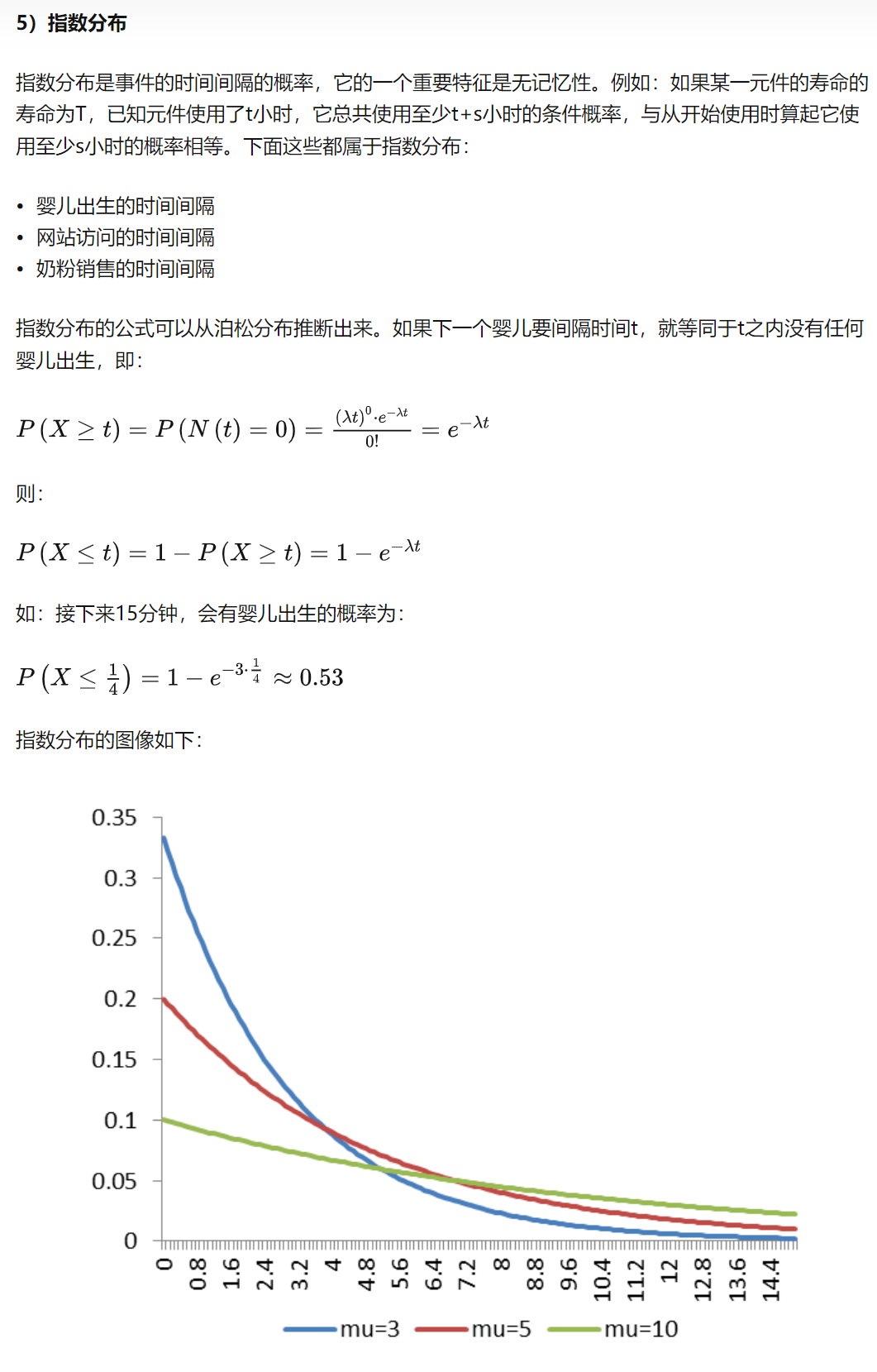
常见分布函数


Lagrange乘子法
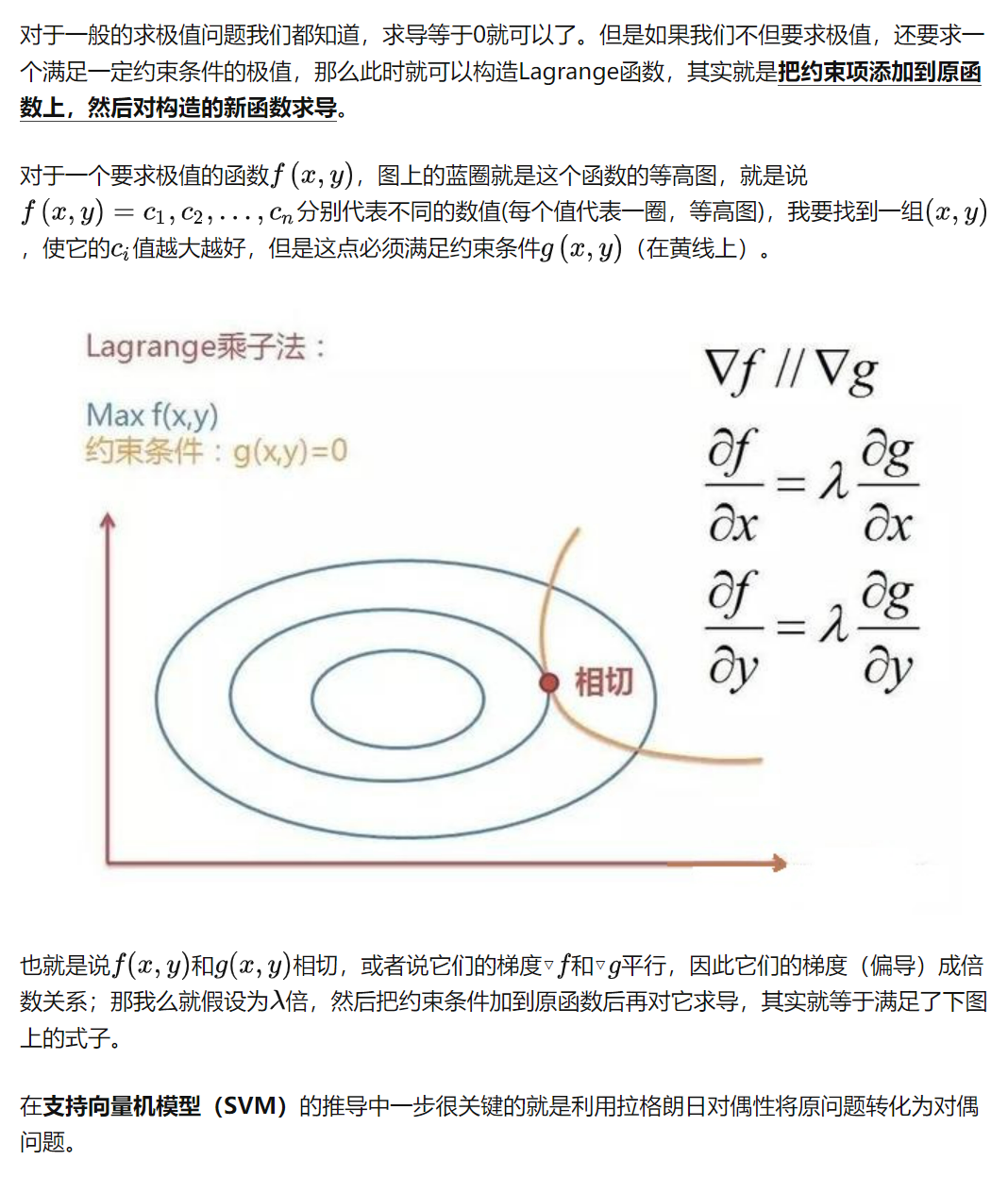
最大似然估计

# 信息论
信息论本来是通信中的概念,但是其核心思想“熵”在机器学习中也得到了广泛的应用。比如决策树模型ID3,C4.5中是利用信息增益来划分特征而生成一颗决策树的,而信息增益就是基于这里所说的熵。所以它的重要性也是可想而知。
熵

联合熵

条件熵

相对熵

互信息

最大熵模型

# 数值计算
上溢和下溢

计算复杂性与NP问题
1、算法复杂性
现实中大多数问题都是离散的数据集,为了反映统计规律,有时数据量很大,而且多数目标函数都不能简单地求得解析解。这就带来一个问题:算法的复杂性。
算法理论被认为是解决各类现实问题的方法论。衡量算法有两个重要的指标:时间复杂度和空间复杂度,这是对算法执行所需要的两类资源——时间和空间的估算。
一般,衡量问题是否可解的重要指标是:该问题能否在多项式时间内求解,还是只能在指数时间内求解?在各类算法理论中,通常使用多项式时间算法即可解决的问题看作是易解问题,需要指数时间算法解决的问题看作是难解问题。
指数时间算法的计算时间随着问题规模的增长而呈指数化上升,这类问题虽然有解,但并不适用于大规模问题。所以当前算法研究的一个重要任务就是将指数时间算法变换为多项式时间算法。
2、确定性和非确定性
除了问题规模与运算时间的比较,衡量一个算法还需要考虑确定性和非确定性的概念。
这里先介绍一下“自动机”的概念。自动机实际上是指一种基于状态变化进行迭代的算法。在算法领域常把这类算法看作一个机器,比较知名的有图灵机、玻尔兹曼机、支持向量机等。
所谓确定性,是指针对各种自动机模型,根据当时的状态和输入,若自动机的状态转移是唯一确定的,则称确定性;若在某一时刻自动机有多个状态可供选择,并尝试执行每个可选择的状态,则称为非确定性。
换个说法就是:确定性是程序每次运行时产生下一步的结果是唯一的,因此返回的结果也是唯一的;非确定性是程序在每个运行时执行的路径是并行且随机的,所有路径都可能返回结果,也可能只有部分返回结果,也可能不返回结果,但是只要有一个路径返回结果,那么算法就结束。
在求解优化问题时,非确定性算法可能会陷入局部最优。
3、NP问题
有了时间上的衡量标准和状态转移的确定性与非确定性的概念,我们来定义一下问题的计算复杂度。
P类问题就是能够以多项式时间的确定性算法来对问题进行判定或求解,实现它的算法在每个运行状态都是唯一的,最终一定能够确定一个唯一的结果——最优的结果。
NP问题是指可以用多项式时间的非确定性算法来判定或求解,即这类问题求解的算法大多是非确定性的,但时间复杂度有可能是多项式级别的。
但是,NP问题还要一个子类称为NP完全问题,它是NP问题中最难的问题,其中任何一个问题至今都没有找到多项式时间的算法。
机器学习中多数算法都是针对NP问题(包括NP完全问题)的。
数值计算
上面已经分析了,大部分实际情况中,计算机其实都只能做一些近似的数值计算,而不可能找到一个完全精确的值,这其实有一门专门的学科来研究这个问题,这门学科就是——数值分析(有时也叫作“计算方法”);运用数值分析解决问题的过程为:实际问题→数学模型→数值计算方法→程序设计→上机计算求出结果。
计算机在做这些数值计算的过程中,经常会涉及到的一个东西就是“迭代运算”,即通过不停的迭代计算,逐渐逼近真实值(当然是要在误差收敛的情况下)。
# 最优化
最优化理论
无论做什么事,人们总希望以最小的代价取得最大的收益。在解决一些工程问题时,人们常会遇到多种因素交织在一起与决策目标相互影响的情况;这就促使人们创造一种新的数学理论来应对这一挑战,也因此,最早的优化方法——线性规划诞生了。
在李航博士的《统计学习方法》中,其将机器学习总结为如下表达式:
机器学习 = 模型 + 策略 + 算法
可以看得出,算法在机器学习中的 重要性。实际上,这里的算法指的就是优化算法。在面试机器学习的岗位时,优化算法也是一个特别高频的问题,大家如果真的想学好机器学习,那还是需要重视起来的。
最优化问题的数学描述

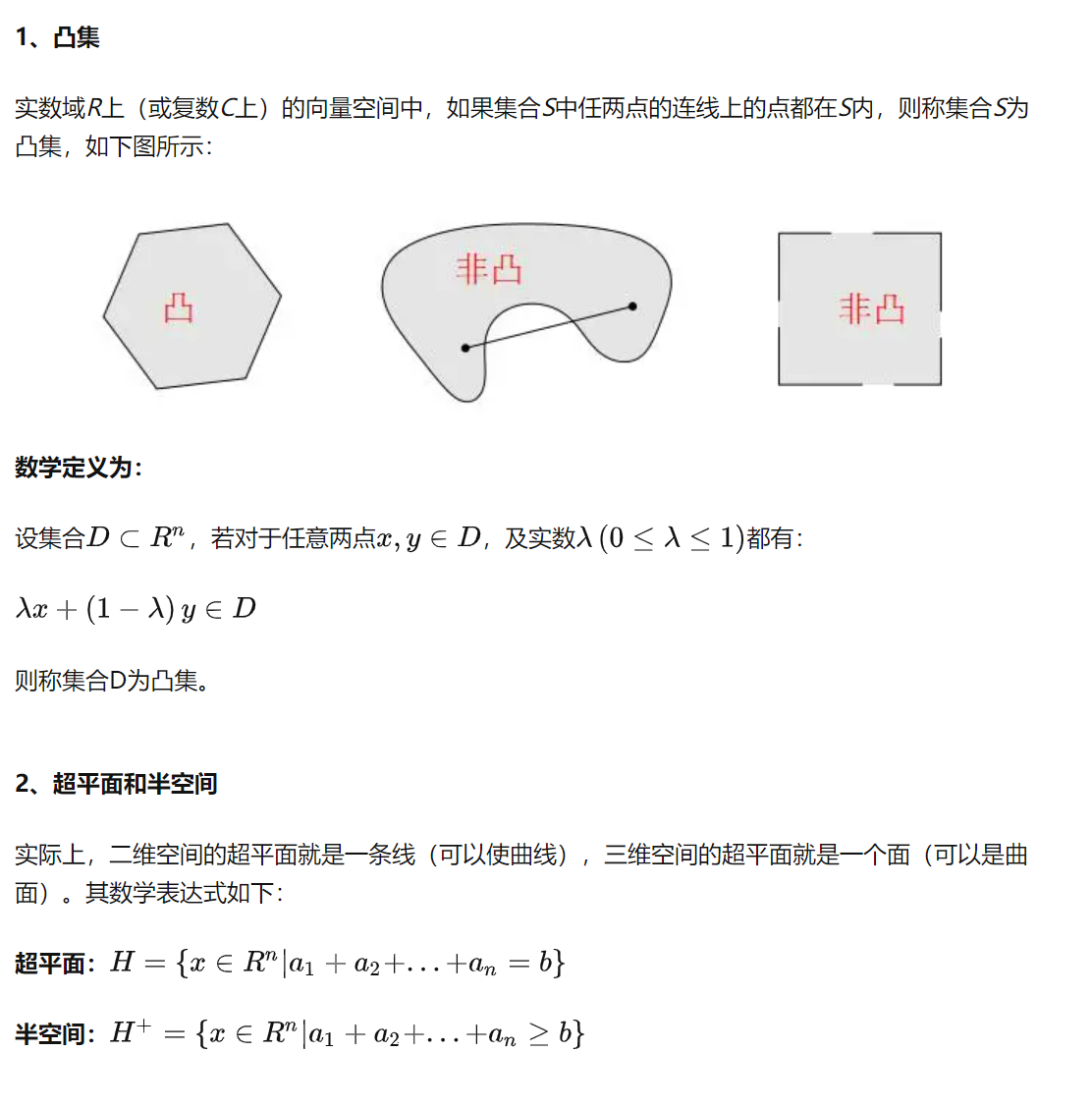
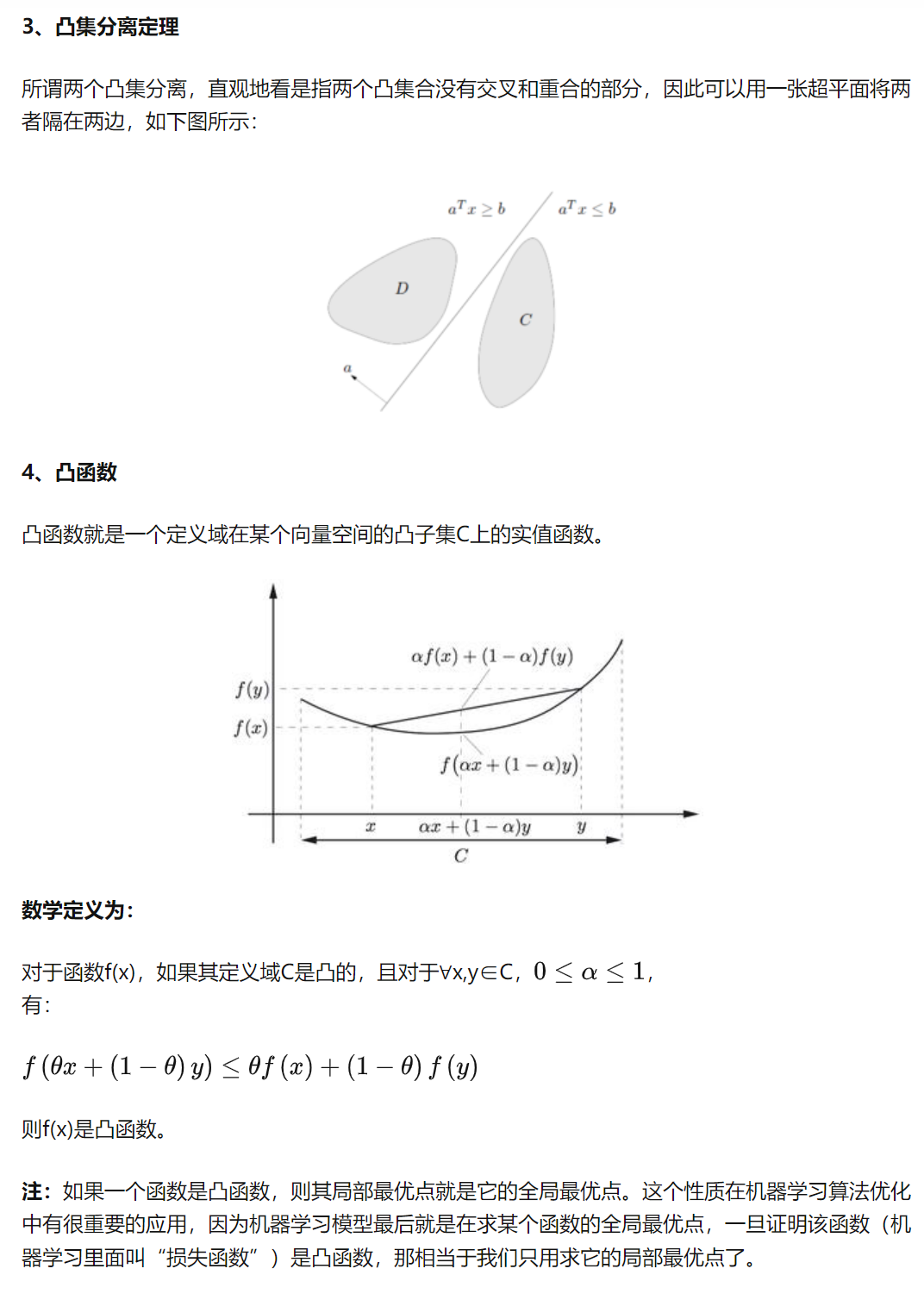
凸集与凸集分离定理
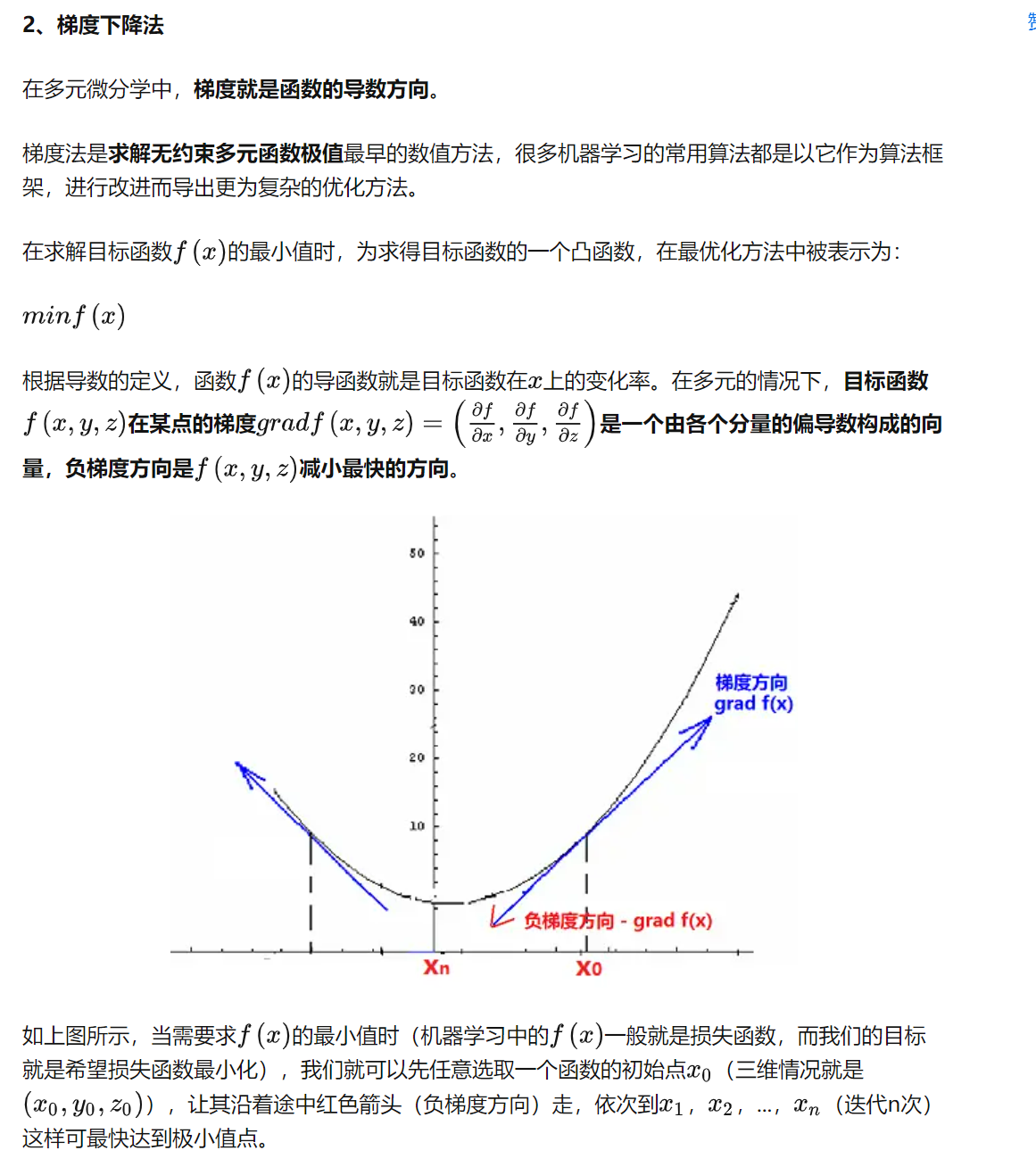
梯度下降算法
1、引入
前面讲数值计算的时候提到过,计算机在运用迭代法做数值计算(比如求解某个方程组的解)时,只要误差能够收敛,计算机最后经过一定次数的迭代后是可以给出一个跟真实解很接近的结果的。
这里进一步提出一个问题,如果我们得到的目标函数是非线性的情况下,按照哪个方向迭代求解误差的收敛速度会最快呢?
答案就是沿梯度方向。这就引入了我们的梯度下降法。

随机梯度下降算法
上面可以看到,在梯度下降法的迭代中,除了梯度值本身的影响外,还有每一次取的步长也很关键:步长值取得越大,收敛速度就会越快,但是带来的可能后果就是容易越过函数的最优点,导致发散;步长取太小,算法的收敛速度又会明显降低。因此我们希望找到一种比较好的方法能够平衡步长。
随机梯度下降法并没有新的算法理论,仅仅是引进了随机样本抽取方式,并提供了一种动态步长取值策略。目的就是又要优化精度,又要满足收敛速度。
也就是说,上面的批量梯度下降法每次迭代时都会计算训练集中所有的数据,而随机梯度下降法每次迭代只是随机取了训练集中的一部分样本数据进行梯度计算,这样做最大的好处是可以避免有时候陷入局部极小值的情况(因为批量梯度下降法每次都使用全部数据,一旦到了某个局部极小值点可能就停止更新了;而随机梯度法由于每次都是随机取部分数据,所以就算局部极小值点,在下一步也还是可以跳出)
两者的关系可以这样理解:随机梯度下降方法以损失很小的一部分精确度和增加一定数量的迭代次数为代价,换取了总体的优化效率的提升。增加的迭代次数远远小于样本的数量。
牛顿法
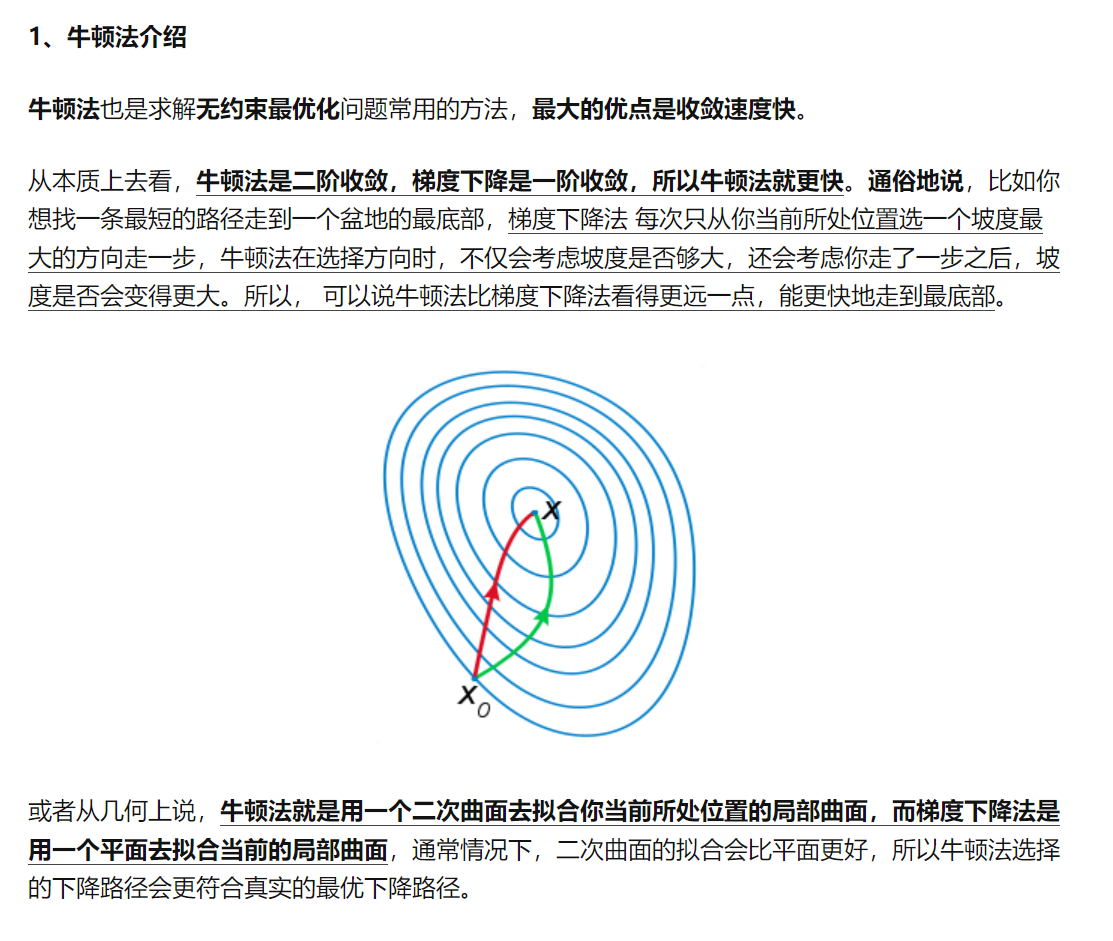

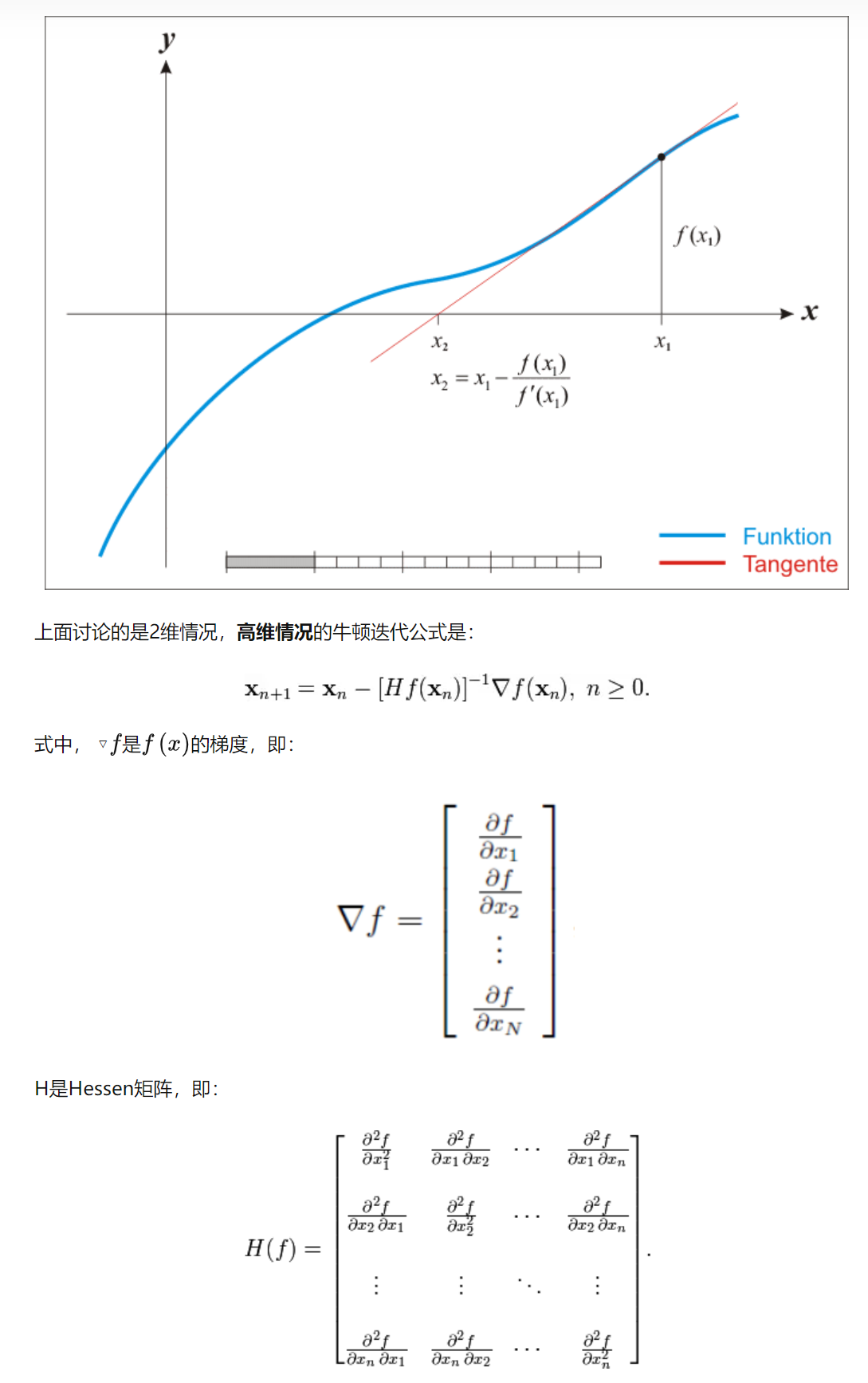

阻尼牛顿法

拟牛顿法
